Hybrid Data Governance: Detecting and Protecting Hidden PII using AI
Executive Summary
Traditional, manual approaches to data governance can no longer keep up with modern data environments—especially as AI and LLMs are embedded into analytics workflows. Sensitive data and PII are often hidden in unstructured text, mislabeled fields, and evolving datasets where schema-based tagging and human review routinely fail.
This article demonstrates an AI-driven Proof of Concept (PoC) that detects PII by analyzing actual data values rather than relying on column names or metadata. The system successfully identifies sensitive information embedded in both structured and unstructured data, generating a PII inventory that drives automated governance actions such as masking and tokenization.
By prioritizing high recall for high-risk identifiers and pairing automation with human-in-the-loop oversight for edge cases, organizations can shift from reactive remediation to proactive protection—significantly reducing compliance risk and preventing unintended PII exposure before data enters analytics and AI pipelines.
Introduction
In my previous article published on January 6, 2026, I explored the fundamentals of Hybrid Governance—establishing robust frameworks for managing known sensitive fields and Personally Identifiable Information (PII). While that foundation is essential for compliance, modern data landscapes require a more rigorous framework to secure data even before a human reviews the data and classifies sensitive fields and PII. Moreover, the manual review and tagging process is laborious, and it is highly unlikely that any enterprise will be able to flag all sensitive data and PII through manual efforts alone.
In today’s data landscape, the major challenge is identifying PII hiding in plain sight: unstructured notes, mislabeled columns, vast amounts of data dumped into data lakes, and sensitive information buried deep within documents. To address this challenge, I developed an Advanced Proof of Concept (PoC) that shifts the paradigm from manual tagging to automated intelligence, using AI to detect, classify, and secure data at scale.
This article intentionally focuses on the discovery and classification layer—because governance controls are only as strong as the intelligence that informs them.
Challenges with Traditional Sensitive Data and PII Tagging
Numerous challenges exist within traditional frameworks for detecting and governing sensitive data and PII. To understand why a move toward automated intelligence is necessary, let’s review these risks in detail.
Emerging AI & LLM Risks
Usage of LLMs & AI Capabilities
Organizations are rapidly integrating LLMs into daily workflows. Many third-party software providers (e.g., Snowflake) now offer native AI capabilities. Without automated detection, sensitive data and PII may be inadvertently exposed to these LLMs.
Hidden PII in Unstructured Data
Manual reviews primarily rely on column or field names (e.g., Name, SSN, DOB, Address). However, PII buried in unstructured data is often missed, posing a significant risk if not handled properly. As more enterprises leverage cloud computing and dump data into data lakes, this risk is elevated.
For example, enterprises experimenting with AI by building RAG (Retrieval-Augmented Generation) architectures often create knowledge bases (vector databases) using historical chat transcripts. If these transcripts contain sensitive information—such as full names, addresses, or SSNs used for identity verification—and are not governed, the chatbot may expose that information to users or to the underlying LLM through the prompt context.
AI and Analytics Pipeline
When sensitive data is pushed into an analytical pipeline—knowingly or unknowingly—it becomes extremely difficult to trace or retract, especially once it is integrated into reports and dashboards. Once sensitive data enters an analytics or AI pipeline, the cost of remediation increases exponentially.
Architectural & Data Flow Risks
Shadow Data and Informal Storage
While data may be secured in a database, it is often extracted and stored on platforms such as SharePoint or sent via email without proper controls. This “shadow data” moves outside the reach of traditional governance mechanisms.
Upstream and Downstream System Impact (Schema Drift)
Applications depend on data feeds from other systems. If an upstream system modifies its schema attributes, the downstream system may fail to flag newly introduced sensitive fields, leading to accidental exposure of PII.
PII Drift Over Time
Data originally deemed non-sensitive may become sensitive as additional attributes are added (for example, adding customer identifiers to transaction metadata). When fields are reviewed manually, a previously “safe” field that has evolved into a sensitive one can easily slip through the cracks.
Foundational & Human Risks
Manual Tagging and Its Repercussions
Traditional governance of sensitive data and PII requires deep knowledge of the data being sourced, ingested, and stored in order to apply appropriate controls. Considering the massive volume of data generated every second, reviewing data manually to detect PII is highly labor-intensive, operationally unscalable, and inherently inconsistent. This leads to missed opportunities for tagging PII, opening a digital door for potential security vulnerabilities.
Lack of Common Understanding
Despite training, the understanding of PII varies across an organization because individuals lack the same context. Employees may mistakenly believe PII is a “package” of fields and that a person can only be identified if all data pointers are present. In reality, a full name combined with a city and state is often sufficient to identify an individual—especially given that data brokers openly list personal information for sale online.
Why This Matters for CIOs and CTOs
For technology leaders, the challenge is no longer whether PII exists, but whether the organization can detect it fast enough, at scale, and before it enters AI, analytics, and reporting pipelines. This PoC demonstrates how automated intelligence can act as an early-warning mechanism, reducing downstream rework, compliance risk, and unintended AI exposure.
Automated PII Detection Using AI
Using AI-driven PII detection enables organizations to identify sensitive fields with greater speed and consistency than manual review and tagging.
PoC Architecture Overview
The PoC consists of an AI-driven scanning layer that evaluates raw data values rather than relying on schema or metadata. This scanning layer produces a PII inventory, which then informs downstream governance actions such as masking, tokenization, and reporting. I selected Presidio for its extensibility, entity-level detection capabilities, and suitability for schema-agnostic analysis.
In this PoC, the system scans and evaluates the content of each column or field rather than relying on column headers or labels. By analyzing data patterns and contextual signals—including unstructured text—the AI engine correctly identified PII even when the information was stored in generically named columns or buried within free-form text.
Input Synthetic Data File
The synthetic dataset used in this PoC contains 250 records and includes three intentionally generic fields:
- field_0, containing address or location data
- Column_1, containing Social Security Numbers (SSNs)
- Unstructured_Notes, containing multiple PII entities such as names, addresses, SSNs, and dates of birth
The table below outlines the data structure of the synthetic dataset used in this PoC.
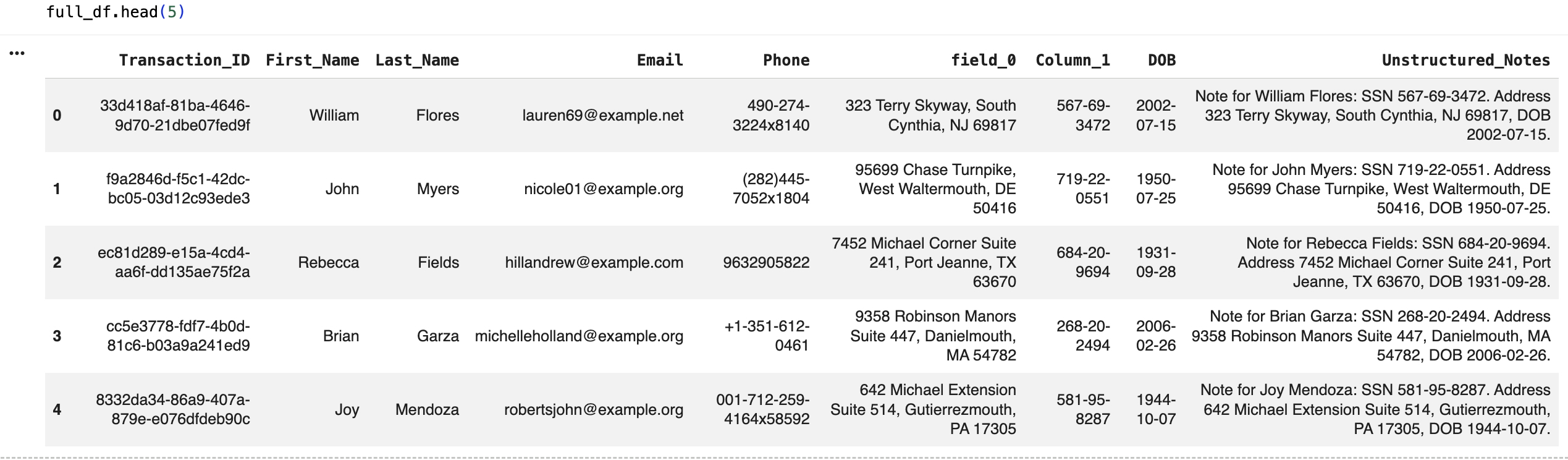
PII Detection Using AI
Presidio Analyzer was used to detect PII by scanning and analyzing column values rather than flagging fields based on their names. The code is schema-agnostic and works across datasets with generic or inconsistent column headers.
The model correctly identified columns containing PII, as shown below:
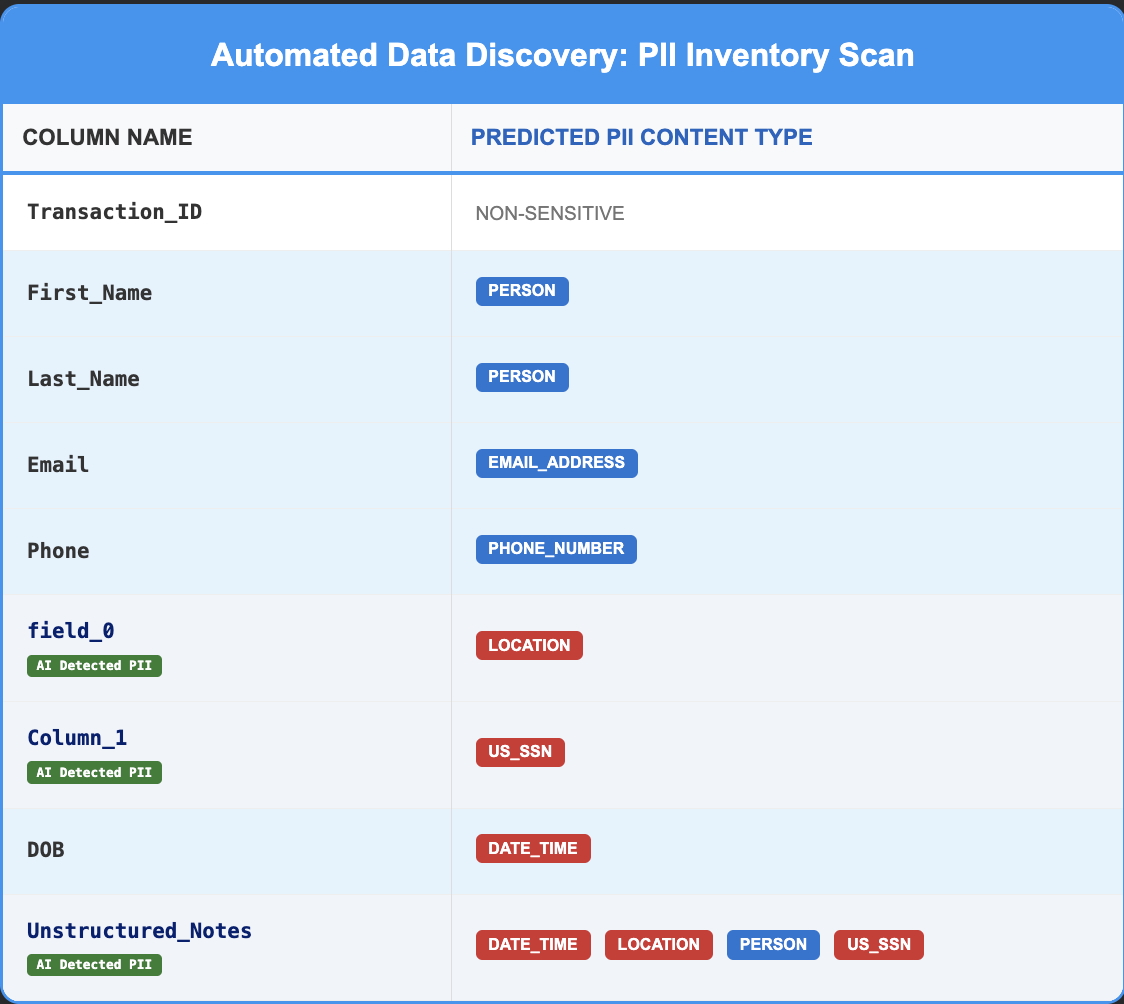
PII Detection in Structured Data
The column field_0 contained address data, and the Presidio Analyzer successfully identified it as LOCATION, even though the column name was randomized. Similarly, Column_1 contained Social Security Numbers, which Presidio correctly classified as US_SSN despite the non-descriptive column header. This demonstrates the model's ability to identify sensitive data based on content rather than metadata alone.
PII Detection in Unstructured Data
The Unstructured_Notes column contained names, SSNs, addresses, and dates of birth embedded within free-form text. The Presidio Analyzer successfully isolated and identified each of these PII entities. This confirms that the engine can maintain high accuracy even when processing complex, multi-entity strings within a single unstructured field.
Model Fine-Tuning and Observations
As with any model development effort, the Presidio Analyzer required fine-tuning to improve classification accuracy. The following challenges were encountered and addressed:
- Multi-Entity Detection
- Issue: The analyzer stopped scanning text after identifying the most obvious PII entity.
- Solution: The logic was updated to continue scanning until the end of the text, ensuring all PII entities were captured.
- Context-Aware Tie-Breaking
- Issue: Street names containing human names (e.g., Christopher Street) were misclassified as PERSON entities.
- Solution: The detection logic was enhanced to consider contextual patterns and metadata signals, allowing the system to intelligently reclassify ambiguous tokens as LOCATION entities based on the surrounding data environment.
- Filtering the Noise
- Issue: Numeric sequences were frequently misclassified as phone numbers, and “.com” strings were flagged as websites.
- Solution: A confidence filter was introduced to suppress weak predictions and deduplicate overlapping categories.
Results and Analysis
The PoC processed the full synthetic dataset and generated a consolidated governance report with PII inventory:

Unstructured text was also analyzed, with the AI detector successfully identifying multiple PII entities within free-form notes:
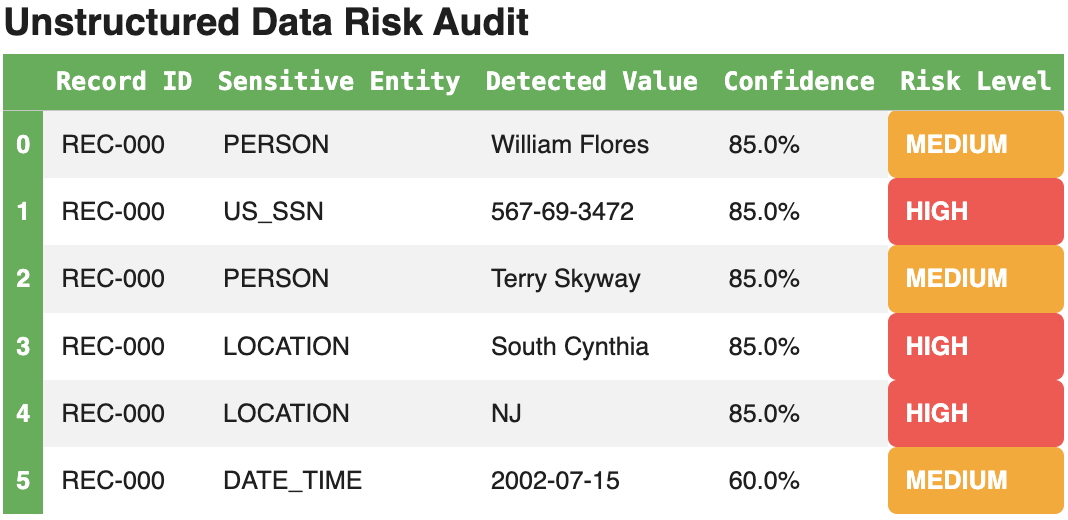
Policy-based governance actions were then applied to mask names, phone numbers, dates of birth, and addresses, while non-reversible tokenization was applied to email addresses and SSNs. The reports below outline the governance frameworks for finalized and unstructured columns:
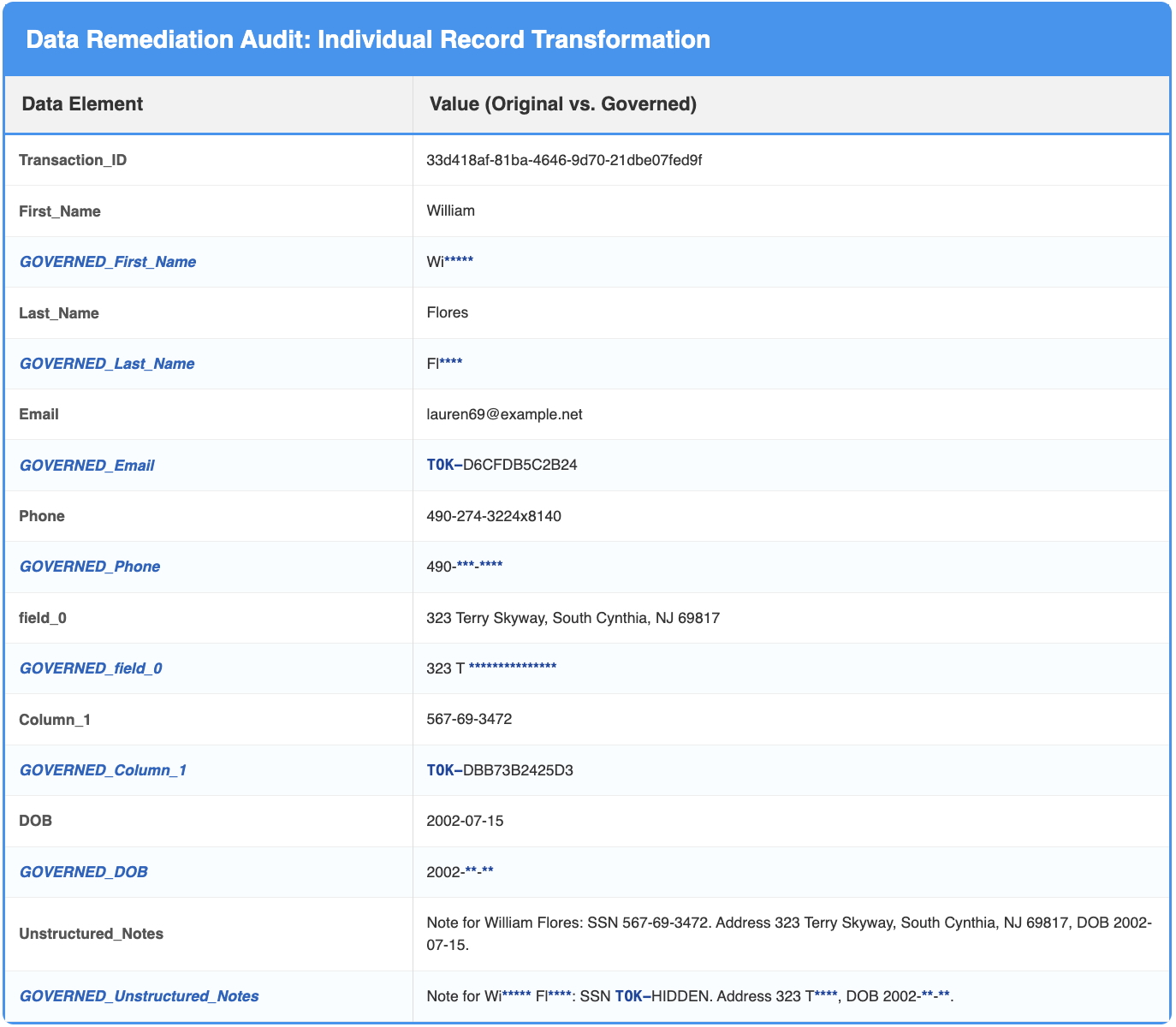
The PoC demonstrated a clear distinction between structured and unstructured detection. While US_SSN detection achieved 100% recall, the LOCATION entity (field_0) initially struggled, reaching 81.2% recall after fine-tuning.
Manual inspection of the records that led to the 18.8% False Negative rate revealed that it was primarily driven by non-standard and military postal formats. While the AI easily identified common street addresses, it frequently bypassed complex strings such as:
- PSC 4380, Box 3731, APO AE 55963
- Unit 7366 Box 3184, DPO AP 41337
- USCGC Archer, FPO AP 17363
Because these formats lack traditional geographic "anchors" (like Street or Avenue) and use specialized military state codes (like APO, DPO, FPO), they fall into an NLP "blind spot."
From a risk perspective, this tradeoff remains highly manageable. By achieving 100% recall on high-stakes identifiers like SSNs, PII exposure is significantly reduced. For more ambiguous entities like these specialized addresses, the PoC demonstrates that a Human-in-the-Loop workflow is inevitable. By automating the bulk of the discovery, the system allows data stewards to transition from manual "searching" to high-value exception handling, where they can validate these specific edge cases and feed corrections back into the model to refine and increase performance over time.
The recall metrics for SSN and field_0 (Location), along with the confusion matrix heatmap for field_0, are provided below:


Understanding the Confusion Matrix
The Confusion Matrix is a performance summary of our AI’s predictions. In the context of PII discovery, each quadrant represents a different risk profile:
- True Positive (TP): The AI correctly identified PII. Goal: Maximize this.
- True Negative (TN): The AI correctly identified non-sensitive data as safe. This reduces "governance fatigue."
- False Positive (FP): The AI flagged safe data as PII. This leads to unnecessary masking.
- False Negative (FN): The AI missed actual PII. This is the highest risk, as it leads to "leaked" data.
What is "Recall" and Why Does It Matter?
In Data Governance, Recall (also known as Sensitivity) is the most critical metric. It measures the AI's ability to find all relevant instances of PII within a dataset.
- High Recall (e.g., 100% for SSNs): This means the system caught every single Social Security Number in the file. No "toxic" data slipped through the cracks.
- The Trade-off: We prioritize high recall for high-risk identifiers because the cost of a miss (False Negative) is far higher than the cost of a manual review (False Positive).
Conclusion: Scaling Trust in the AI Era
The intent of this PoC was to demonstrate that AI can be used to detect PII stored in structured datasets with generic column names, as well as multi-entity PII buried in unstructured notes or documents. By leveraging artificial intelligence for discovery, organizations can move from a reactive security posture to a more proactive governance model.
As enterprises accelerate AI adoption, automated PII discovery is no longer an enhancement—it is a prerequisite for scaling trust, compliance, and innovation.
#CIO #CTO #CDO #DataGovernance #AIGovernance #DataPrivacy #RiskManagement #EnterpriseAI